@brief
早上地铁充值时有位大妈有东西掉了, 和工作人员沟通了几分钟, 本来就睡晚了, 最后差点导致上班迟到 = =
然后突然想到这就是单线程啊… 于是就有了这篇关于 scheduler algorithm 的笔记
原文
what is scheduler
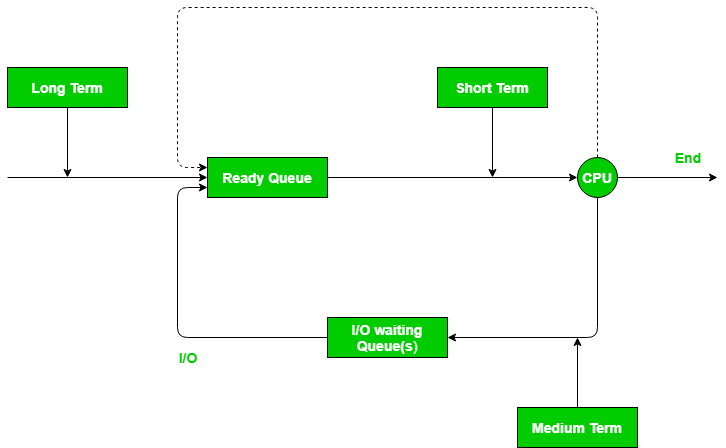
Schedulers are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. There are three types of Scheduler:
schedulers 是特殊的系统软件, 通过多种方式控制进程调度. 它们主要的任务是选择任务并提交到系统, 决定哪个进程执行, 这里有三种类型的 scheduler
Long term (job) scheduler – Due to the smaller size of main memory initially all program are stored in secondary memory. When they are stored or loaded in the main memory they are called process. This is the decision of long term scheduler that how many processes will stay in the ready queue. Hence, in simple words, long term scheduler decides the degree of multi-programming of system.
因为主存空间较小, 最初, 所有的程序都存储在次级内存, 当它们排序或加载到主存时, 称其为进程. 这取决于 long term scheduler , 它决定有多少进程保留在你准备队列中, 因此, 简单来说, long term scheduler 决定了系统的多程序程度
(PS: 这里指的应该是内存和硬盘, 关于 secondary memory, 可以参考 secondary memory)
Medium term scheduler – Most often, a running process needs I/O operation which doesn’t requires CPU. Hence during the execution of a process when a I/O operation is required then the operating system sends that process from running queue to blocked queue. When a process completes its I/O operation then it should again be shifted to ready queue. ALL these decisions are taken by the medium-term scheduler. Medium-term scheduling is a part of swapping.
运行中的进程经常需要 I/O 操作而并非 CPU. 因此在进程执行期间, 当需要 I/O 操作时, 操作系统将当前进程从运行中队列发送到阻塞队列. 当进程完成它的 I/O 操作时, 应该再次将它移回准备队列. 所有这些操作都由 medium-term scheduler 决定, medium-term scheduling 是 swapping 的一部分
Short term (CPU) scheduler – When there are lots of processes in main memory initially all are present in the ready queue. Among all of the process, a single process is to be selected for execution. This decision is handled by short term scheduler.Let’s have a look at the figure given below. It may make a more clear view for you.
当由大量的进程在准备队列时, 在所有的进程中, 只有一个进程被选择执行. 这由 short term scheduler 决定.
(PS: 关于 CPU burst time, determine burst time)
difference scheduling algorithms
First Come First Serve (FCFS): Simplest scheduling algorithm that schedules according to arrival times of processes. First come first serve scheduling algorithm states that the process that requests the CPU first is allocated the CPU first. It is implemented by using the FIFO queue. When a process enters the ready queue, its PCB is linked onto the tail of the queue. When the CPU is free, it is allocated to the process at the head of the queue. The running process is then removed from the queue. FCFS is a non-preemptive scheduling algorithm.
最简单的调度算法根据时间进程的时间顺序调度. 先到先得调度算法声明最先请求 CPU 的进程最先被处理. 其使用 FIFO 队列实现. 当进程进入准备队列时, PCB 链接到队列的尾部(??? 啥东西???) 当 CPU 空闲时, CPU 资源被分配给队列头部的进程. 运行中进程从队列中移除, FCFS 是一个非抢先式的调度算法
Note:First come first serve suffers from convoy effect.
FCFS 受 convoy effect 影响
Shortest Job First (SJF): Process which have the shortest burst time are scheduled first.If two processes have the same bust time then FCFS is used to break the tie. It is a non-preemptive scheduling algorithm.
拥有最短突发时间的进程优先调度. 当两个进程拥有同样的突发时间时, FCFS 用于解决这种情况. 它同样是一个非抢占调度算法
Longest Job First (LJF): It is similar to SJF scheduling algorithm. But, in this scheduling algorithm, we give priority to the process having the longest burst time. This is non-preemptive in nature i.e., when any process starts executing, can’t be interrupted before complete execution.
类似 SJF 调度算法, 但是, 在这个调度算法中, 给予最长突发时间优先权限. 这同样也是非抢占式的. 当进程开始执行时, 不能在完成执行前被打断
Shortest Remaining Time First (SRTF): It is preemptive mode of SJF algorithm in which jobs are schedule according to shortest remaining time.
是 SJF 调度算法的抢占版本, 根据最少剩余时间调度
Longest Remaining Time First (LRTF): It is preemptive mode of LJF algorithm in which we give priority to the process having largest burst time remaining.
LJF 算法的抢占模式, 给予最大突发时间剩余进程优先权限
Round Robin Scheduling: Each process is assigned a fixed time(Time Quantum/Time Slice) in cyclic way.It is designed especially for the time-sharing system. The ready queue is treated as a circular queue. The CPU scheduler goes around the ready queue, allocating the CPU to each process for a time interval of up to 1-time quantum. To implement Round Robin scheduling, we keep the ready queue as a FIFO queue of processes. New processes are added to the tail of the ready queue. The CPU scheduler picks the first process from the ready queue, sets a timer to interrupt after 1-time quantum, and dispatches the process. One of two things will then happen. The process may have a CPU burst of less than 1-time quantum. In this case, the process itself will release the CPU voluntarily. The scheduler will then proceed to the next process in the ready queue. Otherwise, if the CPU burst of the currently running process is longer than 1-time quantum, the timer will go off and will cause an interrupt to the operating system. A context switch will be executed, and the process will be put at the tail of the ready queue. The CPU scheduler will then select the next process in the ready queue.
每个进程每个周期被分配一个固定的时间(时间量子/时间片), 这特别为时间共享系统所设计. 准备队列被视作一个循环的队列. CPU 调度循环准备队列. 分配 CPU 资源给每个进程最多一个的时间量.
为了实现 round robin scheduling 将准备队列依旧保持为 FIFO 队列, 新的进程在队列的尾端加入, CPU 从队列的头部选取一个进程, 设置在一个时间量后中断的定时器, 派发这个进程. 这个进程的 CPU 突发可能少于1个时间量, 在这种情况下, 进程会自动释放 CPU 资源, 调度器继续处理准备队列的下一个进程, 其他情况下, 如果当前进程 CPU burst 超过1个时间片, 将会触发定时器, 向操作系统发出一个中断. 将会执行内容切换, 进程将会重新放入准备队列的尾端. CPU 调度将会选择准备队列的下一个进程, 以此循环.
Priority Based scheduling (Non-Preemptive): In this scheduling, processes are scheduled according to their priorities, i.e., highest priority process is scheduled first. If priorities of two processes match, then schedule according to arrival time. Here starvation of process is possible.
在这个调度下, 进程根据他们的优先级调度, 比如, 高优先级的进程会有限调度. 如果两个进程的优先级相等. 则根据他们的先后顺序调度, 有可能出现饥饿线程
Highest Response Ratio Next (HRRN): In this scheduling, processes with highest response ratio is scheduled. This algorithm avoids starvation.
Response Ratio = (Waiting Time + Burst time) / Burst time
在这种调度下, 拥有高响应比的进程有限调度, 这个算法避免饥饿
Multilevel Queue Scheduling: According to the priority of process, processes are placed in the different queues. Generally high priority process are placed in the top level queue. Only after completion of processes from top level queue, lower level queued processes are scheduled. It can suffer from starvation.
根据进程的优先级, 进程被放置在不同的队列. 通常, 高优先级的进程被放置在上层队列. 只有在完成上层队列中的进程后, 低层队列中的进程才会被调度, 它有可能挨饿
Multi level Feedback Queue Scheduling: It allows the process to move in between queues. The idea is to separate processes according to the characteristics of their CPU bursts. If a process uses too much CPU time, it is moved to a lower-priority queue.
允许进程在队列中移动, 这个想法根据它们的 CPU 突发特性区分进程, 如果进程使用过多的 CPU 时间, 它将会被移动到低优先级的队列
Some useful facts about Scheduling Algorithms:
FCFS can cause long waiting times, especially when the first job takes too much CPU time.
FCFS 可能导致长时间等待, 特别是当第一个任务执行太久时
Both SJF and Shortest Remaining time first algorithms may cause starvation. Consider a situation when the long process is there in the ready queue and shorter processes keep coming.
SJF 和 shortest remaining time first 算法可能导致饥饿, 考虑当长的进程在准备队列中, 但一直有短进程不断加入的情景
If time quantum for Round Robin scheduling is very large, then it behaves same as FCFS scheduling.
如果 round robin 调度的时间量太长时, 情况类似于 FCFS 调度
SJF is optimal in terms of average waiting time for a given set of processes,i.e., average waiting time is minimum with this scheduling, but problems are, how to know/predict the time of next job.
就给定一组进程的平均等待时间而言, SJF 是最优的, 但是问题在于, 如何预测下一个任务的执行时间





